这是前一段时间投稿给《程序员》的一篇文章。标题中的"道"有些大了,您可以理解为"门道"的"道"。一家之言,妄自言道,诚可笑也。
什么是网站运维(Web operations) ?运维,绝不是某些人眼中安装系统、做几根网线那么简单? 除去应用开发和业务运营之外的保障网站能运转的事儿都可能是运维工作的职责范围。运维的工作包括(但不限于) 软硬件部署、网络管理、应用程序维护、安全、容量规划、故障修复等等。
运维,有别于”运营”。在中文的语境中,运营更多和业务结合在一起的。而运维,则是偏向技术层面。
任何一个成功的站点都离不开一只优秀的运维团队,尽管他们更多时候隐身在网站背后不为人知。
网站可用性
所谓网站可用性(availability)也即网站正常运行时间的百分比,这是每个运营团队最主要的 KPI (Key Performance Indicators ,关键业绩指标)。对于 Web 站点来说,传统的那个 24×7 的说法已经不是很适用了,现在业界更倾向用 N 个9 来量化可用性, 最常说的就是类似 “4个9(也就是99.99%)” 的可用性。看一下表 1 能更为直观一些。
| 描述 | 通俗叫法 | 可用性级别 | 年度停机时间 |
| 基本可用性 | 2个9 | 99% | 87.6小时 |
| 较高可用性 | 3个9 | 99.9% | 8.8小时 |
| 具有故障自动恢复能力的可用性 | 4个9 | 99.99% | 53分钟 |
| 极高可用性 | 5个9 | 99.999% | 5分钟 |
根据墨菲定理的推论,世界上没有 100% 可靠的 Web站点(除非不运行)。业界网站的可用性都是多少?引人注目的 Web 新贵 Twitter (http://twitter.com), 2008 年前四个月的可用性只有 98.72%,有 37小时 16分钟不能提供服务,连2个9 都达不到,甚至还没达到”基本可用”状态。电子商务巨头 eBay 2007 年的可用性是 99.94%,考虑到 eBay 站点的规模与应用的复杂程度,这是个很不错可用性指标了。Web 应用类型决定了不同的站点对可用性的依赖性是不同的。 要知道 4 个 9 的可用性实际上是很难实现的目标。至于 5 个9 的 Web 站点,一半靠内功,另一半恐怕是要靠点运气。
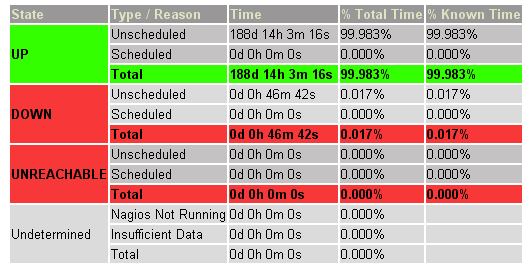
(图1 维基百科网站的一台数据库服务器的可用情况报告, 由Nagios的监控得到的)
多数情况下,网站可用性会是 SLA (Service Level Agreement, 服务水平协议) 中的一个重要度量指标,也是运维团队向自己的客户(更多是公司老板)的正式承诺。可用性是能够持续改进的东西,KPI 制定者切不可狮子大开口,企图一步登天,拍拍脑袋提一些不太切实的指标。运维团队对可用性的承诺也不能开些空头支票,到头来两头难看。值得强调的是,如果是做第三方托管,更需要明确 SLA,明了第三方的服务能力,否则,费尽了九牛二虎之力终于保证了软硬件网络等环节都没问题了,IDC 却频繁断电或者IDC 出口网络不可用,这也绝对做不到预期的高可用性。
提高可用性的一些常规策略有消除单点,部署冗余设备(或集群),配置带外管理网络等,对可用性要求不高的网站这些可能足够了。如果要提供更高的可用性,比如 4 个 9 甚至 5 个9,就不是简单靠硬件就能做到的事情,还需要建立完善的流程制度、建立变更机制、提升事故响应速度等。正所谓是”没有最高可用,只有更高可用性”。
一般来说,所有的网站运维人员都在追求网站的更高级别的高可用性,但是必须注意,这是以额外的软硬件投入、更多的人力成本为代价的。成本与可用性之间也请做到良好的平衡,盲目追求高可用性是不可取的。
(补充:Twitter 的可用性现在已经有了很大提升,但是可以看到,可用性不佳并非一个网站的杀手,只要产品对用户足够友好,足够有粘度,足够不可或缺,那么可用性并非是第一要追求的运维目标。有些运维人员被 Amazon 的某年圣诞节期间宕机所造成的影响埋下心理阴影,其实没那么可怕,如果真的觉得可怕,那么你可能被一些厂商销售人员洗脑了。)
未完待续: 下一篇《监控与报警》
Fenng终于结束流水账了…
成本与可用性之间也请做到良好的平衡,盲目追求高可用性是不可取的。
这句很赞同,尤其是对于还没有盈利的互联网公司
更期待《监控与报警》带来的头脑风暴,现在的思路基本局限于Nagios了
言之有理~~~用系统原理来说就是“强调个体效能的发挥,并不是要求系统中每个子系统都必须具有最优的性能。”(避免浪费精力)
@suchasplus
其实我更愿意写流水帐
过两天, 找到 亚马逊 DBA 写的宕机原文, 拿来娱乐兼反省一下.
几年不会有down机了,老美没有那么多消费需求了
配置带外管理网络
是指什么?
带外管理就是OUT-BAND,相对于带内管理(IN-BAND)一词,是一个范畴,比如通过远程网卡统一管理server,storage等,即使server掉电,也能remote power on。带内管理举个例子比如通过KVM直接连接server
@dragonlady
晕, 原来服务器加一块远程管理卡就是所谓带外管理了
好文,收藏至20ju.com
关于可用性 有些问题希望和楼主讨论
比如 我费了半天劲 作了 网络冗余 机器冗余
各种备份回复策略
甚至菜油发电机等等
然后比照idc提供给我的sla 我可以向老板保证 我们网站的sla了
结果 . 某天 我们的search的页面. 不小被几个人同时访问了
结果 数据库挂了.结果 首页
但80还开着. 老板暴跳如雷. 你们都是吃屎的?
这种情况下的sla该如何计算? 我永远不知道 我所保证的服务器上跑的应用都有什么潜在的危险.这种情况下该如何保证.
或者极端的说.就算你提供的是一个apache的index自己的首页.
其他啥应用都没有. 你怎么保证你的机器不被ddos攻击. 或者忽然apapche出了个大bug好几天没有更新. 这种情况下 该如何计算可用性.???
所以我一直以为 可用性 分为可计算 和不可计算的. 而我们基本是无法分清什么是可计算什么是不可计算的. 一段有不可以计算部分 我们中国人基本都充分利用不可计算的混沌优势. 比如某次我某个应用挂了.正好电信出了点小问题.得. 这下好 全算电信头上吧.
@beta
你说的几种情况其实也是可用性范围内的事情。search 页面设计的时候要考虑容量,同时运维人员也应该从旧有的数据中发现系统比较脆弱的点,这是责无旁贷的事情。
至于被 DDos 攻击、软件 Bug , 也同样如此。被DDos 攻击在极端的时候可能抵挡不了,但应该有个预防措施和解决方案吧?软件Bug,平时要多注意以一些,发现问题解决问题,而不是等问题出现的时候你才发现有个 Bug。
运维就是个平衡的事情,不能绝对,但需要渐进改进;也需要提高意识。