拜读了关于 LinkedIn 几位工程师写的构建 TB 级的 key-value 系统的经验:Building a terabyte-scale data cycle at LinkedIn with Hadoop and Project Voldemort。具体实现过程有大致的描述,就不鹦鹉学舌了。
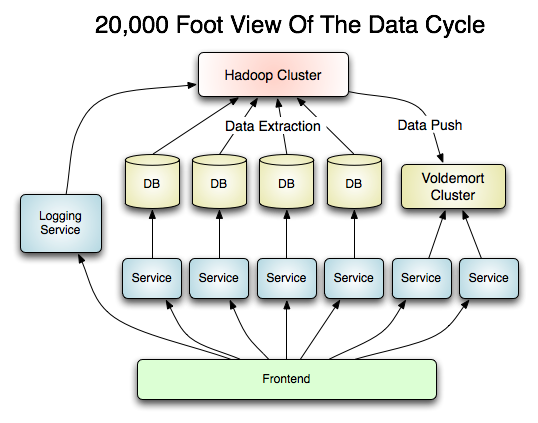
其实现在很多公司可能都面临着这个抽象架构图中的类似问题。以 Hadoop 作为后端的计算集群,计算得出来的数据如果要反向推到前面去,用什么方式存储更为恰当? 再放到 DB 里面的话,构建索引是麻烦事;放到 Memcached 之类的 Key-Value 分布式系统中,毕竟只是在内存里,数据又容易丢。Voldemort 算是一个不错的改良方案。
值得借鉴的几点:
- 键(Key)结构的设计,有点技巧;
- 架构师熟知硬件结构是有用的。越大的系统越是如此。
- 用好并行。Amdahl 定律以后出现的场合会更多。
关于 key-value 应用的解决方案又多了一种。LinkedIn 对此应用案例也还在发展中。如果业务类型类似,不妨关注一下。
–EOF–
正需要这方面的东西.
一个与voldemort无关的话题。
前段时间在你这里留言,你说你购买了256MB的Dreamhost的VPS,今天通过你的phpsysinfo看到,你有400MB的可用内存,自己升级了一下?
@Jackie
在 Dreamhost 后台可以随时更改
哦,是不是你修改多一点的内存,然后这个月的就多支付点就可以了?
Good!虽然不是从事web架构,不过还是学习到了!Thx
老大阅读量也真的是很广呀
这个系统和伏地魔有啥子关系吗。。
Tokyo Cabinet/Tokyo Tyrant (称它 ttserver) 也是 key/value 分布式 key-value 存储系统,它与 memcached 一样,是在客户端实现分布策略。
据说 ttserver 很高效。tokyocabinet.sourceforge.net
不知 Voldemort 与 ttserver 性能怎么样。
Voldemort 与 ttserver 做的不是同一件事情。 Voldemort 是只读的
key value 存储,它是在后端 Hadoop 上生成的,使用简单的文件格式存储。
它关注的是,如何高效的部署到线上供只读使用,如何快速的更新版本而不影响
线上服务,如何在出错的时候快速回滚等等。
可以看看我做的一个简单的 ppt:LinkedIn Voldemort 简单介绍:
http://www.slideshare.net/tangfl/voldemort-intro-tangfl?type=presentation