按:此为客座博文系列。投稿人吴朱华曾在IBM中国研究院从事与云计算相关的研究,现在正致力于研究云计算技术。
本篇是本系列的最终章,将总结一下App Engine在使用方面的注意点,最佳实践和适用场景,最后会谈一下我对App Engine的一些期望。
注意点
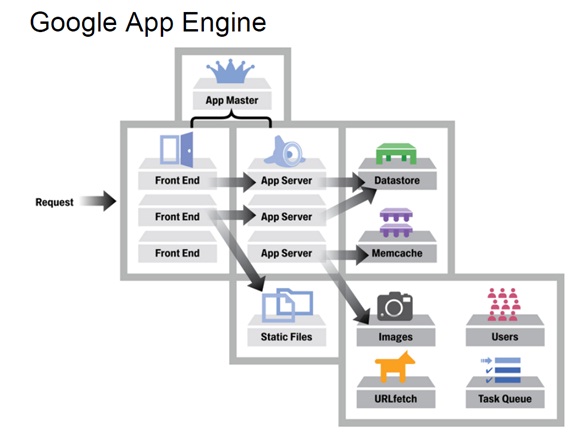
- 执行速度偏慢:由于其分布式的设计,所以在速度方面不是最优的,比如普通的Memcache能在几毫秒完成操作,而App Engine的Memcache则大概需要50(毫)秒才能完成操作。
- 私有API:其API有很多都是私有,特别是在其服务方面,虽然Google提供了很不错的文档,但是在学习和移植等方面,成本都很高。
- 执行会出现失败的情况:根据很多人的实际经验,App Engine会不定时出现执行失败的情况,特别是Datastore和URLFetch这两部分,虽然Google已经将Datastore方面出现错误的几率从原先的0.4降至现在的0.1,但是失败的情况是很难避免的。
- 有时会停机:虽然总体而言,停机并不频繁,但是在今年初出现长达136分钟故障导致部分用户的应用无法正常运行,其发生原因来自于其备份数据中心出现了问题。
- 无法选择合适的数据中心:比如,你应用所面对的用户主要在欧洲,但是你应用所属App Engine服务器却很有可能是被部署在一个美国的数据中心内,虽然你的应用很有可能在将来移动至欧洲某个数据中心,但是你却无法控制整个过程。
- 有时会处理请求超时:虽然能平均在100至200ms之间完成海量的请求,但是有时会出现处理请求超时的情况。
- 不支持裸域名:只支持类似CNAME的子域名。
最佳实践
- 适应App Engine的数据模型:因为其数据模型,并不是传统的关系模式,而且在性能方面表现也和关系型数据库差别很大,所以如果想要用好非常关键的Datastore,那么理解和适应其数据模型是不可或缺的。
- 对应用进行切分:由于App Engine对每个应用都有一定资源限制,而且为了让应用更SOA化和更模块化,可以对一个应用切分多个子应用,比如,可以分成一个用于前端的Web应用和多个用于REST服务的后台应用。
- 极可能多地利用Memcache,这样不仅能减少昂贵的Datastore操作,而且能减轻Datastore的压力。
- 在上面提到过,由于App Engine在执行某些操作时会出现失败的情况,比如Datastore方面,所以要在设计和实现这两方面做好相应的异常处理工作。
- 由于Datastore不是关系型数据库,导致在执行常见的求总数操作时显的有点”捉襟见肘”,所以最好使用Google推荐的Sharded Counters技术来计算总数。
- 由于Blobstore还只是刚走出试验期而已,而且其他模块对静态文件(比如图片等)支持不佳,比如Datastore只支持1MB以内的对象,同时每个应用只能最多上传一千个文件,而且速度不是最优,所以推荐使用其他专业的云存储,比如Amazon的S3或者Google马上就要推出的Google Storage等。
- 尽量使用批处理方式,不论是在使用Datastore还是发送邮件等。
- 不要手动创建Index:因为App Engine会自动根据你在代码中查询来创建相关的Index。
适用场景
现在而言,App Engne主要适用于下面这三个场景:
- Web Hosting:这是最常见的场景,在App Engine上已经部署了数以十万计的小型网站(其中有很多主要为了学习目的),而且还部署了一些突发流量很大的网站,其中最著名的例子就是美国白宫的”Open For Questions”这个站点,主要用于让美国人民给奥巴马总统提问的,这个站点在短短的几个小时内处理接近百万级别的流量。
- REST服务:这也是在App Engine平台上很常见的场景,最出名的例子就是BuddyPoke,BuddyPoke的客户端就是一个Flash应用,在用户的浏览器上运行,而它的服务器端则是以REST服务的形式放置在App Engine上,每当Flash客户端需要读取和存储数据的时候,它都会发请求给后端的REST服务,来让其执行相关的Datastore操作。
- 依赖Google服务的应用:比如应用能够通过App Engine的Email服务来发送大规模的电子邮件。
未来的期望
- 更稳定的表现,更少的超时异常和更快的反应速度,特别是在Datastore和Memcached这两方面。
- 支持对数据中心的选择,虽然现在App Engine会根据应用的用户群的所在地来调整应用所在的数据中心,但由于整个过程对开发者而言是不可控的,所以希望能在创建应用的时候,能让用户自己选择合适的数据中心。
- SLA,如果App Engine能像S3那样设定一些SLA条款,这样将使用户更放心地在App Engine上部署应用。
- 新的语言:比如PHP,但是如果在现有的App Engine架构上添加一门新的语言,整个工作量会非常大的,因为App Engine有接近一半的模块是语言特定的,比如应用服务器和开发环境等,所以短期内我认为不太可能支持新的语言。
总体而言,Google App Engine是Google大战略中一个不可分割的一部分,因为Google希望能通过App Engine来降低Web应用开发的难度,只要难度降低了,那么Web应用替代客户端应用的整体速度将会加快,如果出现这样的情况的话,那么将会对Google今后的发展非常有利。
本系列文章结束。
参考资料:
- Google’s Dr. Kai-Fu Lee on Cloud Computing
- The Cost of Latency
- Google App Engine Blog
- Bigtable: A Distributed Storage System for Structured Data
- From Spark Plug to Drive Train: Life of an App Engine Request
- Google Megastore
- Google App Engine官方文档
- Google Architecture
- Google App Engine – a first look
- Google Chose Jetty for App Engine
- Google App Engine is Down – Backup Data Center Having Problems
- 面向虚拟基础设施的云服务,第 2 部分: Platform as a Service (PaaS) 和 AppScale
- 传Google正在开发新的服务器文件系统
- Google File System
- Designs, Lessons and Advice from Building Large Distributed Systems
- The Chubby lock service for loosely-coupled distributed systems
- Google’s Will Power and Data Center Efficiency
- MapReduce
- MapReduce的论文
- Protocol Buffer 简介
- Google data centers snub Africa, Oz, and anything near Wyoming Or do they?
- Google揭秘服务器创新技术 内置电池替换UPS
- 开源数据库 Sharding 技术(Share Nothing)
- Google File System II: Dawn of the Multiplying Master Nodes
- Transactions Across Datacenters
- 探秘Google全球数据中心与中国机房
- 揭开Google数据中心五大神话
- 俄勒冈州的Google数据中心耗电惊人
- Google App Engine For Java – Microblogging Case Study
- Under the covers of the App Engine Datastore
- Google Megastore
- Megastore/Bigtable Replication的文章
–EOF–